Bringing Spatial Data Processing to Apache Wayang



Apache Wayang already enables a large variety of data processing workflows, ranging from basic data retrieval and filtering to complex ML tasks. However, there are additional areas that could benefit from its platform flexibility. As part of a university project, we implemented spatial operators in Apache Wayang. This enables the execution of workflows using geospatial data, including spatial join and filter operations. Since execution times can differ significantly depending on the chosen platform, spatial workflows can benefit greatly from Wayang’s cross-platform capabilities.
Implementation
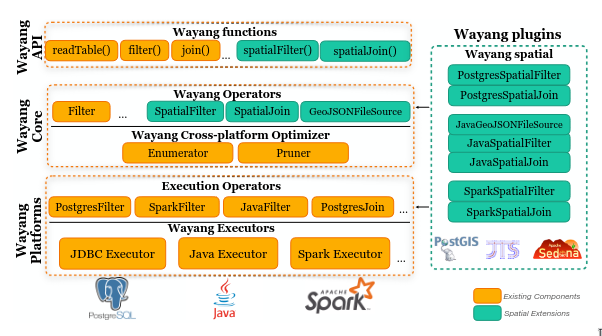
Workflows including spatial operators are not the main task in Apache Wayang. Therefore, we chose to add spatial support as a plugin that can be enabled separately.
The two new operators we added are SpatialFilter and SpatialJoin, since many spatial workflows primarily rely on these two operations.
To support multiple data sources and geometry formats, we introduced an internal geometry representation, SpatialGeometry, that enables translation between formats. This allows geometries stored as WKT, WKB, and GeoJSON to be read and, if necessary, converted to the type expected by the consuming operator.
For the execution of spatial jobs, we currently support Java, PostgreSQL, and Spark as backends. The Spark implementation uses Apache Sedona, a well-established library for distributed processing of spatial data. The Java implementation is based on JTS, and the PostgreSQL platform uses PostGIS for spatial operations.
WayangContext wayangContext = new WayangContext(configuration)
.withPlugin(Java.basicPlugin())
.withPlugin(Postgres.plugin())
.withPlugin(Spatial.plugin());
final Collection<Long> outputcount = builder
.readTable(new PostgresTableSource(tableName, "ST_AsText(geom)"))
.spatialFilter(
(input -> WayangGeometry.fromStringInput(input.getString(0))),
SpatialPredicate.INTERSECTS,
queryGeometry
).withSqlGeometryColumnName("geom")
.withTargetPlatform(Postgres.platform())
.count()
.collect();
System.out.println("Spatial Filter Postgres Result Size: " + outputcount);
Why Spatial Is a Plugin, Not a Platform
In the current Wayang architecture, a platform is responsible for runtime ownership: it defines a Platform implementation, provides an executor factory, defines channel conversions, and integrates cost models. This can be seen clearly in modules such as Java (JavaPlatform + JavaExecutor) and PostgreSQL (PostgresPlatform via JdbcPlatformTemplate + JdbcExecutor).
The spatial extension is intentionally different. It does not introduce a new Platform subclass and does not provide its own executor. Instead, wayang-spatial is implemented as a plugin (Spatial.java) that contributes operators, mappings for those operators, and specifies required platforms.
The logical spatial operators (SpatialFilterOperator, SpatialJoinOperator, GeoJsonFileSource) still live in wayang-basic and are included in the Java-Scala API. The spatial plugin extends the system by adding platform-specific execution operators and transformation rules that map Wayang operators to their platform implementations.
At registration time, WayangContext.withPlugin(...) calls plugin.configure(configuration). This whitelists the required platforms and spatial mappings. During optimization, mappings such as SpatialFilterMapping and SpatialJoinMapping rewrite logical operators into execution operators such as:
JavaSpatialFilterOperator/JavaSpatialJoinOperatorSparkSpatialFilterOperator/SparkSpatialJoinOperatorPostgresSpatialFilterOperator/PostgresSpatialJoinOperator
Execution is then handled by the existing platform runtimes:
- Java operators are executed by
JavaExecutor - Spark operators are executed by
SparkExecutor - PostgreSQL operators are executed through the JDBC runtime (
JdbcExecutor)
In practice, this is why applications have to register both a platform plugin (for general operators and channels) and a spatial plugin (for spatial mappings), for example Java.basicPlugin() + Spatial.javaPlugin() or Spark.basicPlugin() + Spatial.sparkPlugin().
This design provides three concrete advantages:
- No duplicate runtime stack, since executors, channels, and cost models remain centralized in the platforms
- Clean multi-platform support for the same spatial semantics
- Lower maintenance overhead, because spatial development efforts can focus on operator logic and mappings rather than recreating infrastructure
Spatial support in Wayang is therefore best understood as a cross-platform capability extension: it contributes spatial semantics and translation, while execution remains fully owned by the underlying platforms.
Benchmarks
Below we show scenarios where it is advantageous to be able to freely choose the execution depending on the use case. The following benchmarks are not intended to be exhaustive tests of our new operators but rather to highlight how using the platform independence of Apache Wayang can speed up spatial jobs. We executed the benchmarks on an HPC cluster with reproducible Spark cluster configurations.
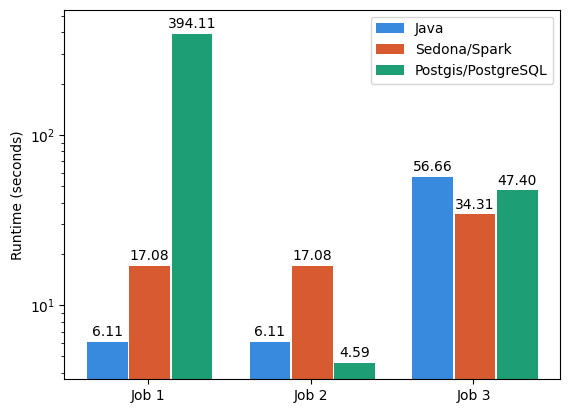
- Job 1: Spatial Join of parks (~44k) and lakes (~140k) in Germany with spatial predicate CONTAINS, no index on Postgres tables, Spark cluster with 4 nodes
- Job 2: Spatial Join of parks (~44k) and lakes (~140k) in Germany with spatial predicate CONTAINS, spatial index on Postgres tables, Spark cluster with 4 nodes
- Job 3: Spatial Join of two synthetic datasets containing boxes (100k and 1M) with spatial predicate INTERSECTS, spatial index on Postgres tables, Spark cluster with 8 nodes
The above figure shows that there are use cases in which each of the currently supported platforms performs best. For small datasets, Java performs best if there is no spatial index available for Postgres; otherwise, Postgres outperforms Java. Due to the Spark overhead, Sedona running on a Spark cluster only gains an advantage in jobs with large datasets, as seen in Job 3.
This is also evident in the following figure. While Java and Postgres perform better than Sedona on a Spark cluster for joins on small datasets, this trend reverses for joins of larger datasets. Especially for the join of 100k and 10M boxes (generated using star.cs.ucr.edu), the Spark cluster outperforms the single node execution of Java and Postgres. The poor performance of Sedona/Spark on a cluster with only one node indicates that this advantage is actually coming from the distributed workload and not just from using Sedona instead of JTS or PostGIS operators.
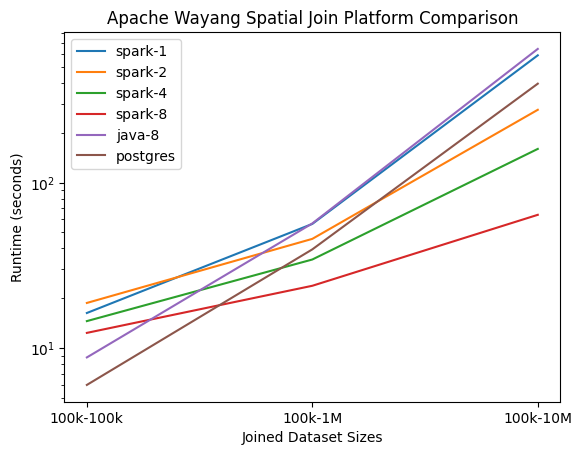
The performance gained by using larger cluster configurations can also be seen in the following visualization of runtime results of box joins with datasets of various sizes.
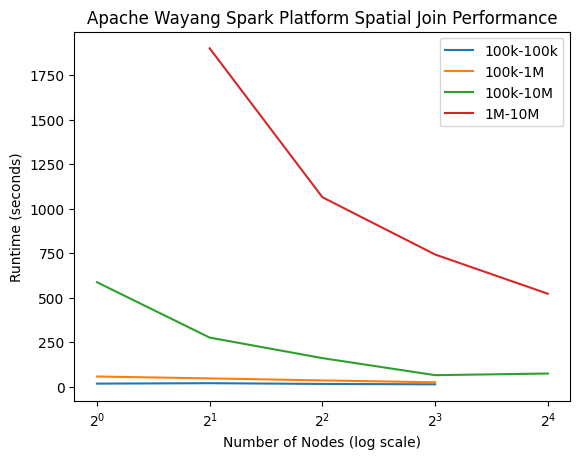
Other than dataset size, selectivity and subsequently the join result size can also impact execution time significantly. The following chart shows the execution time of joining synthetic box datasets containing 1M boxes each. For each run, one of the datasets contained boxes with decreasing max edge lengths, resulting in higher selectivity for the intersection join. Execution times for Java decreased significantly with decreasing box edge lengths, while execution times for the Spark platform stayed roughly the same.
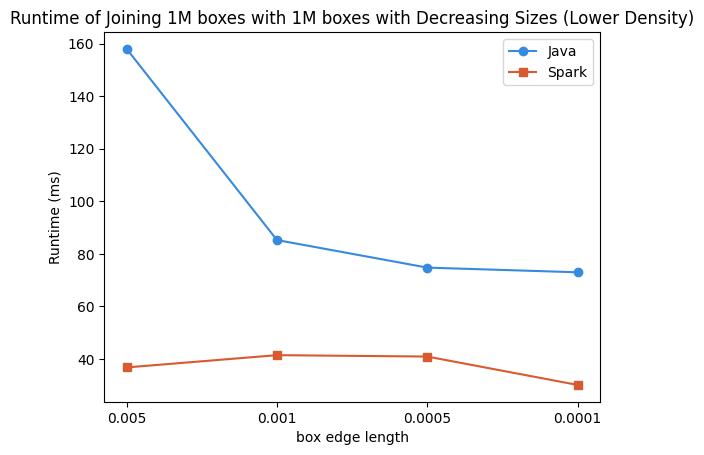
The benchmark results show multiple scenarios in which platform choice has a significant impact on runtime. Spatial data processing can therefore benefit greatly from using the new spatial operators in Apache Wayang.
Future Work
Our spatial extension enables basic spatial workloads using filter and join operations on the Java, Spark, and Postgres platforms. However, additional operators like nearest neighbor or within-distance operations could enable even more complex scenarios.
Adding platforms specifically designed for spatial data processing could improve performance even further. An interesting candidate for this could be the relatively recently introduced Apache SedonaDB database engine.
Currently, the execution platform has to be chosen manually. Part of potential future work should therefore be the implementation of heuristics for platform selection.