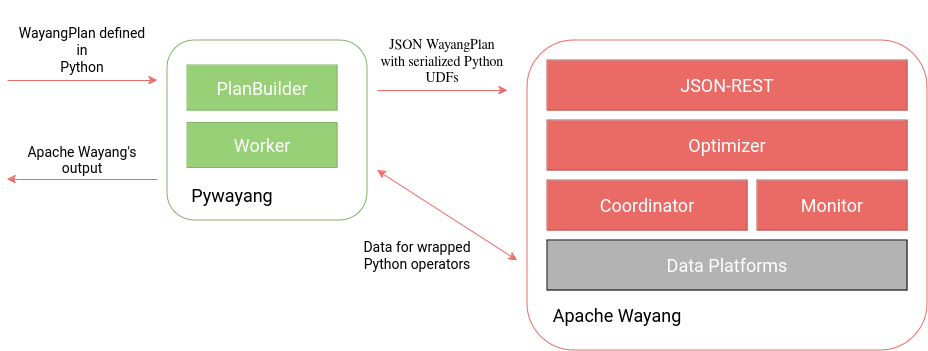
[INFO] [ERROR] Failed to execute goal org.apache.maven.plugins:maven-deploy-plugin:3.0.0-M1:deploy (default-deploy) on project wayang: ArtifactDeployerException: Failed to deploy artifacts: Could not transfer artifact org.apache.wayang:wayang:pom:1.0.0-RC2 from/to apache.releases.https (https://repository.apache.org/service/local/staging/deploy/maven2): NullPointerException -> [Help 1]
[INFO] org.apache.maven.lifecycle.LifecycleExecutionException: Failed to execute goal org.apache.maven.plugins:maven-deploy-plugin:3.0.0-M1:deploy (default-deploy) on project wayang: ArtifactDeployerException
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.doExecute2 (MojoExecutor.java:333)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.doExecute (MojoExecutor.java:316)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:212)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:174)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.access$000 (MojoExecutor.java:75)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor$1.run (MojoExecutor.java:162)
[INFO] at org.apache.maven.plugin.DefaultMojosExecutionStrategy.execute (DefaultMojosExecutionStrategy.java:39)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:159)
[INFO] at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:105)
[INFO] at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:73)
[INFO] at org.apache.maven.lifecycle.internal.builder.singlethreaded.SingleThreadedBuilder.build (SingleThreadedBuilder.java:53)
[INFO] at org.apache.maven.lifecycle.internal.LifecycleStarter.execute (LifecycleStarter.java:118)
[INFO] at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:261)
[INFO] at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:173)
[INFO] at org.apache.maven.DefaultMaven.execute (DefaultMaven.java:101)
[INFO] at org.apache.maven.cli.MavenCli.execute (MavenCli.java:906)
[INFO] at org.apache.maven.cli.MavenCli.doMain (MavenCli.java:283)
[INFO] at org.apache.maven.cli.MavenCli.main (MavenCli.java:206)
[INFO] at jdk.internal.reflect.NativeMethodAccessorImpl.invoke0 (Native Method)
[INFO] at jdk.internal.reflect.NativeMethodAccessorImpl.invoke (NativeMethodAccessorImpl.java:62)
[INFO] at jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke (DelegatingMethodAccessorImpl.java:43)
[INFO] at java.lang.reflect.Method.invoke (Method.java:566)
[INFO] at org.codehaus.plexus.classworlds.launcher.Launcher.launchEnhanced (Launcher.java:283)
[INFO] at org.codehaus.plexus.classworlds.launcher.Launcher.launch (Launcher.java:226)
[INFO] at org.codehaus.plexus.classworlds.launcher.Launcher.mainWithExitCode (Launcher.java:407)
[INFO] at org.codehaus.plexus.classworlds.launcher.Launcher.main (Launcher.java:348)
[INFO] Caused by: org.apache.maven.plugin.MojoExecutionException: ArtifactDeployerException
[INFO] at org.apache.maven.plugins.deploy.DeployMojo.deployProject (DeployMojo.java:201)
[INFO] at org.apache.maven.plugins.deploy.DeployMojo.execute (DeployMojo.java:159)
[INFO] at org.apache.maven.plugin.DefaultBuildPluginManager.executeMojo (DefaultBuildPluginManager.java:126)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.doExecute2 (MojoExecutor.java:328)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.doExecute (MojoExecutor.java:316)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:212)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:174)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.access$000 (MojoExecutor.java:75)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor$1.run (MojoExecutor.java:162)
[INFO] at org.apache.maven.plugin.DefaultMojosExecutionStrategy.execute (DefaultMojosExecutionStrategy.java:39)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:159)
[INFO] at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:105)
[INFO] at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:73)
[INFO] at org.apache.maven.lifecycle.internal.builder.singlethreaded.SingleThreadedBuilder.build (SingleThreadedBuilder.java:53)
[INFO] at org.apache.maven.lifecycle.internal.LifecycleStarter.execute (LifecycleStarter.java:118)
[INFO] at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:261)
[INFO] at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:173)
[INFO] at org.apache.maven.DefaultMaven.execute (DefaultMaven.java:101)
[INFO] at org.apache.maven.cli.MavenCli.execute (MavenCli.java:906)
[INFO] at org.apache.maven.cli.MavenCli.doMain (MavenCli.java:283)
[INFO] at org.apache.maven.cli.MavenCli.main (MavenCli.java:206)
[INFO] at jdk.internal.reflect.NativeMethodAccessorImpl.invoke0 (Native Method)
[INFO] at jdk.internal.reflect.NativeMethodAccessorImpl.invoke (NativeMethodAccessorImpl.java:62)
[INFO] at jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke (DelegatingMethodAccessorImpl.java:43)
[INFO] at java.lang.reflect.Method.invoke (Method.java:566)
[INFO] at org.codehaus.plexus.classworlds.launcher.Launcher.launchEnhanced (Launcher.java:283)
[INFO] at org.codehaus.plexus.classworlds.launcher.Launcher.launch (Launcher.java:226)
[INFO] at org.codehaus.plexus.classworlds.launcher.Launcher.mainWithExitCode (Launcher.java:407)
[INFO] at org.codehaus.plexus.classworlds.launcher.Launcher.main (Launcher.java:348)
[INFO] Caused by: org.apache.maven.shared.transfer.artifact.deploy.ArtifactDeployerException: Failed to deploy artifacts: Could not transfer artifact org.apache.wayang:wayang:pom:1.0.0-RC2 from/to apache.releases.https (https://repository.apache.org/service/local/staging/deploy/maven2): NullPointerException
[INFO] at org.apache.maven.shared.transfer.artifact.deploy.internal.Maven31ArtifactDeployer.deploy (Maven31ArtifactDeployer.java:126)
[INFO] at org.apache.maven.shared.transfer.artifact.deploy.internal.DefaultArtifactDeployer.deploy (DefaultArtifactDeployer.java:79)
[INFO] at org.apache.maven.shared.transfer.project.deploy.internal.DefaultProjectDeployer.deploy (DefaultProjectDeployer.java:190)
[INFO] at org.apache.maven.shared.transfer.project.deploy.internal.DefaultProjectDeployer.deploy (DefaultProjectDeployer.java:134)
[INFO] at org.apache.maven.plugins.deploy.DeployMojo.deployProject (DeployMojo.java:193)
[INFO] at org.apache.maven.plugins.deploy.DeployMojo.execute (DeployMojo.java:159)
[INFO] at org.apache.maven.plugin.DefaultBuildPluginManager.executeMojo (DefaultBuildPluginManager.java:126)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.doExecute2 (MojoExecutor.java:328)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.doExecute (MojoExecutor.java:316)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:212)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:174)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.access$000 (MojoExecutor.java:75)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor$1.run (MojoExecutor.java:162)
[INFO] at org.apache.maven.plugin.DefaultMojosExecutionStrategy.execute (DefaultMojosExecutionStrategy.java:39)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:159)
[INFO] at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:105)
[INFO] at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:73)
[INFO] at org.apache.maven.lifecycle.internal.builder.singlethreaded.SingleThreadedBuilder.build (SingleThreadedBuilder.java:53)
[INFO] at org.apache.maven.lifecycle.internal.LifecycleStarter.execute (LifecycleStarter.java:118)
[INFO] at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:261)
[INFO] at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:173)
[INFO] at org.apache.maven.DefaultMaven.execute (DefaultMaven.java:101)
[INFO] at org.apache.maven.cli.MavenCli.execute (MavenCli.java:906)
[INFO] at org.apache.maven.cli.MavenCli.doMain (MavenCli.java:283)
[INFO] at org.apache.maven.cli.MavenCli.main (MavenCli.java:206)
[INFO] at jdk.internal.reflect.NativeMethodAccessorImpl.invoke0 (Native Method)
[INFO] at jdk.internal.reflect.NativeMethodAccessorImpl.invoke (NativeMethodAccessorImpl.java:62)
[INFO] at jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke (DelegatingMethodAccessorImpl.java:43)
[INFO] at java.lang.reflect.Method.invoke (Method.java:566)
[INFO] at org.codehaus.plexus.classworlds.launcher.Launcher.launchEnhanced (Launcher.java:283)
[INFO] at org.codehaus.plexus.classworlds.launcher.Launcher.launch (Launcher.java:226)
[INFO] at org.codehaus.plexus.classworlds.launcher.Launcher.mainWithExitCode (Launcher.java:407)
[INFO] at org.codehaus.plexus.classworlds.launcher.Launcher.main (Launcher.java:348)
[INFO] Caused by: org.eclipse.aether.deployment.DeploymentException: Failed to deploy artifacts: Could not transfer artifact org.apache.wayang:wayang:pom:1.0.0-RC2 from/to apache.releases.https (https://repository.apache.org/service/local/staging/deploy/maven2): NullPointerException
[INFO] at org.eclipse.aether.internal.impl.DefaultDeployer.deploy (DefaultDeployer.java:278)
[INFO] at org.eclipse.aether.internal.impl.DefaultDeployer.deploy (DefaultDeployer.java:202)
[INFO] at org.eclipse.aether.internal.impl.DefaultRepositorySystem.deploy (DefaultRepositorySystem.java:393)
[INFO] at org.apache.maven.shared.transfer.artifact.deploy.internal.Maven31ArtifactDeployer.deploy (Maven31ArtifactDeployer.java:122)
[INFO] at org.apache.maven.shared.transfer.artifact.deploy.internal.DefaultArtifactDeployer.deploy (DefaultArtifactDeployer.java:79)
[INFO] at org.apache.maven.shared.transfer.project.deploy.internal.DefaultProjectDeployer.deploy (DefaultProjectDeployer.java:190)
[INFO] at org.apache.maven.shared.transfer.project.deploy.internal.DefaultProjectDeployer.deploy (DefaultProjectDeployer.java:134)
[INFO] at org.apache.maven.plugins.deploy.DeployMojo.deployProject (DeployMojo.java:193)
[INFO] at org.apache.maven.plugins.deploy.DeployMojo.execute (DeployMojo.java:159)
[INFO] at org.apache.maven.plugin.DefaultBuildPluginManager.executeMojo (DefaultBuildPluginManager.java:126)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.doExecute2 (MojoExecutor.java:328)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.doExecute (MojoExecutor.java:316)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:212)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:174)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.access$000 (MojoExecutor.java:75)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor$1.run (MojoExecutor.java:162)
[INFO] at org.apache.maven.plugin.DefaultMojosExecutionStrategy.execute (DefaultMojosExecutionStrategy.java:39)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:159)
[INFO] at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:105)
[INFO] at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:73)
[INFO] at org.apache.maven.lifecycle.internal.builder.singlethreaded.SingleThreadedBuilder.build (SingleThreadedBuilder.java:53)
[INFO] at org.apache.maven.lifecycle.internal.LifecycleStarter.execute (LifecycleStarter.java:118)
[INFO] at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:261)
[INFO] at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:173)
[INFO] at org.apache.maven.DefaultMaven.execute (DefaultMaven.java:101)
[INFO] at org.apache.maven.cli.MavenCli.execute (MavenCli.java:906)
[INFO] at org.apache.maven.cli.MavenCli.doMain (MavenCli.java:283)
[INFO] at org.apache.maven.cli.MavenCli.main (MavenCli.java:206)
[INFO] at jdk.internal.reflect.NativeMethodAccessorImpl.invoke0 (Native Method)
[INFO] at jdk.internal.reflect.NativeMethodAccessorImpl.invoke (NativeMethodAccessorImpl.java:62)
[INFO] at jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke (DelegatingMethodAccessorImpl.java:43)
[INFO] at java.lang.reflect.Method.invoke (Method.java:566)
[INFO] at org.codehaus.plexus.classworlds.launcher.Launcher.launchEnhanced (Launcher.java:283)
[INFO] at org.codehaus.plexus.classworlds.launcher.Launcher.launch (Launcher.java:226)
[INFO] at org.codehaus.plexus.classworlds.launcher.Launcher.mainWithExitCode (Launcher.java:407)
[INFO] at org.codehaus.plexus.classworlds.launcher.Launcher.main (Launcher.java:348)
[INFO] Caused by: org.eclipse.aether.transfer.ArtifactTransferException: Could not transfer artifact org.apache.wayang:wayang:pom:1.0.0-RC2 from/to apache.releases.https (https://repository.apache.org/service/local/staging/deploy/maven2): NullPointerException
[INFO] at org.eclipse.aether.connector.basic.ArtifactTransportListener.transferFailed (ArtifactTransportListener.java:44)
[INFO] at org.eclipse.aether.connector.basic.BasicRepositoryConnector$TaskRunner.run (BasicRepositoryConnector.java:417)
[INFO] at org.eclipse.aether.connector.basic.BasicRepositoryConnector.put (BasicRepositoryConnector.java:297)
[INFO] at org.eclipse.aether.internal.impl.DefaultDeployer.deploy (DefaultDeployer.java:271)
[INFO] at org.eclipse.aether.internal.impl.DefaultDeployer.deploy (DefaultDeployer.java:202)
[INFO] at org.eclipse.aether.internal.impl.DefaultRepositorySystem.deploy (DefaultRepositorySystem.java:393)
[INFO] at org.apache.maven.shared.transfer.artifact.deploy.internal.Maven31ArtifactDeployer.deploy (Maven31ArtifactDeployer.java:122)
[INFO] at org.apache.maven.shared.transfer.artifact.deploy.internal.DefaultArtifactDeployer.deploy (DefaultArtifactDeployer.java:79)
[INFO] at org.apache.maven.shared.transfer.project.deploy.internal.DefaultProjectDeployer.deploy (DefaultProjectDeployer.java:190)
[INFO] at org.apache.maven.shared.transfer.project.deploy.internal.DefaultProjectDeployer.deploy (DefaultProjectDeployer.java:134)
[INFO] at org.apache.maven.plugins.deploy.DeployMojo.deployProject (DeployMojo.java:193)
[INFO] at org.apache.maven.plugins.deploy.DeployMojo.execute (DeployMojo.java:159)
[INFO] at org.apache.maven.plugin.DefaultBuildPluginManager.executeMojo (DefaultBuildPluginManager.java:126)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.doExecute2 (MojoExecutor.java:328)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.doExecute (MojoExecutor.java:316)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:212)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:174)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.access$000 (MojoExecutor.java:75)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor$1.run (MojoExecutor.java:162)
[INFO] at org.apache.maven.plugin.DefaultMojosExecutionStrategy.execute (DefaultMojosExecutionStrategy.java:39)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:159)
[INFO] at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:105)
[INFO] at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:73)
[INFO] at org.apache.maven.lifecycle.internal.builder.singlethreaded.SingleThreadedBuilder.build (SingleThreadedBuilder.java:53)
[INFO] at org.apache.maven.lifecycle.internal.LifecycleStarter.execute (LifecycleStarter.java:118)
[INFO] at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:261)
[INFO] at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:173)
[INFO] at org.apache.maven.DefaultMaven.execute (DefaultMaven.java:101)
[INFO] at org.apache.maven.cli.MavenCli.execute (MavenCli.java:906)
[INFO] at org.apache.maven.cli.MavenCli.doMain (MavenCli.java:283)
[INFO] at org.apache.maven.cli.MavenCli.main (MavenCli.java:206)
[INFO] at jdk.internal.reflect.NativeMethodAccessorImpl.invoke0 (Native Method)
[INFO] at jdk.internal.reflect.NativeMethodAccessorImpl.invoke (NativeMethodAccessorImpl.java:62)
[INFO] at jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke (DelegatingMethodAccessorImpl.java:43)
[INFO] at java.lang.reflect.Method.invoke (Method.java:566)
[INFO] at org.codehaus.plexus.classworlds.launcher.Launcher.launchEnhanced (Launcher.java:283)
[INFO] at org.codehaus.plexus.classworlds.launcher.Launcher.launch (Launcher.java:226)
[INFO] at org.codehaus.plexus.classworlds.launcher.Launcher.mainWithExitCode (Launcher.java:407)
[INFO] at org.codehaus.plexus.classworlds.launcher.Launcher.main (Launcher.java:348)
[INFO] Caused by: java.lang.NullPointerException
[INFO] at java.util.concurrent.ConcurrentHashMap.putVal (ConcurrentHashMap.java:1011)
[INFO] at java.util.concurrent.ConcurrentHashMap.put (ConcurrentHashMap.java:1006)
[INFO] at org.apache.http.impl.client.BasicCredentialsProvider.setCredentials (BasicCredentialsProvider.java:62)
[INFO] at org.eclipse.aether.transport.http.DeferredCredentialsProvider.getCredentials (DeferredCredentialsProvider.java:67)
[INFO] at org.apache.http.client.protocol.RequestAuthCache.doPreemptiveAuth (RequestAuthCache.java:135)
[INFO] at org.apache.http.client.protocol.RequestAuthCache.process (RequestAuthCache.java:110)
[INFO] at org.apache.http.protocol.ImmutableHttpProcessor.process (ImmutableHttpProcessor.java:133)
[INFO] at org.apache.http.impl.execchain.ProtocolExec.execute (ProtocolExec.java:184)
[INFO] at org.apache.http.impl.execchain.RetryExec.execute (RetryExec.java:89)
[INFO] at org.apache.http.impl.execchain.ServiceUnavailableRetryExec.execute (ServiceUnavailableRetryExec.java:85)
[INFO] at org.apache.http.impl.execchain.RedirectExec.execute (RedirectExec.java:110)
[INFO] at org.apache.http.impl.client.InternalHttpClient.doExecute (InternalHttpClient.java:185)
[INFO] at org.apache.http.impl.client.CloseableHttpClient.execute (CloseableHttpClient.java:72)
[INFO] at org.eclipse.aether.transport.http.HttpTransporter.execute (HttpTransporter.java:485)
[INFO] at org.eclipse.aether.transport.http.HttpTransporter.implPut (HttpTransporter.java:469)
[INFO] at org.eclipse.aether.spi.connector.transport.AbstractTransporter.put (AbstractTransporter.java:107)
[INFO] at org.eclipse.aether.connector.basic.BasicRepositoryConnector$PutTaskRunner.runTask (BasicRepositoryConnector.java:564)
[INFO] at org.eclipse.aether.connector.basic.BasicRepositoryConnector$TaskRunner.run (BasicRepositoryConnector.java:414)
[INFO] at org.eclipse.aether.connector.basic.BasicRepositoryConnector.put (BasicRepositoryConnector.java:297)
[INFO] at org.eclipse.aether.internal.impl.DefaultDeployer.deploy (DefaultDeployer.java:271)
[INFO] at org.eclipse.aether.internal.impl.DefaultDeployer.deploy (DefaultDeployer.java:202)
[INFO] at org.eclipse.aether.internal.impl.DefaultRepositorySystem.deploy (DefaultRepositorySystem.java:393)
[INFO] at org.apache.maven.shared.transfer.artifact.deploy.internal.Maven31ArtifactDeployer.deploy (Maven31ArtifactDeployer.java:122)
[INFO] at org.apache.maven.shared.transfer.artifact.deploy.internal.DefaultArtifactDeployer.deploy (DefaultArtifactDeployer.java:79)
[INFO] at org.apache.maven.shared.transfer.project.deploy.internal.DefaultProjectDeployer.deploy (DefaultProjectDeployer.java:190)
[INFO] at org.apache.maven.shared.transfer.project.deploy.internal.DefaultProjectDeployer.deploy (DefaultProjectDeployer.java:134)
[INFO] at org.apache.maven.plugins.deploy.DeployMojo.deployProject (DeployMojo.java:193)
[INFO] at org.apache.maven.plugins.deploy.DeployMojo.execute (DeployMojo.java:159)
[INFO] at org.apache.maven.plugin.DefaultBuildPluginManager.executeMojo (DefaultBuildPluginManager.java:126)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.doExecute2 (MojoExecutor.java:328)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.doExecute (MojoExecutor.java:316)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:212)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:174)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.access$000 (MojoExecutor.java:75)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor$1.run (MojoExecutor.java:162)
[INFO] at org.apache.maven.plugin.DefaultMojosExecutionStrategy.execute (DefaultMojosExecutionStrategy.java:39)
[INFO] at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:159)
[INFO] at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:105)
[INFO] at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:73)
[INFO] at org.apache.maven.lifecycle.internal.builder.singlethreaded.SingleThreadedBuilder.build (SingleThreadedBuilder.java:53)
[INFO] at org.apache.maven.lifecycle.internal.LifecycleStarter.execute (LifecycleStarter.java:118)
[INFO] at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:261)
[INFO] at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:173)
[INFO] at org.apache.maven.DefaultMaven.execute (DefaultMaven.java:101)
[INFO] at org.apache.maven.cli.MavenCli.execute (MavenCli.java:906)
[INFO] at org.apache.maven.cli.MavenCli.doMain (MavenCli.java:283)
[INFO] at org.apache.maven.cli.MavenCli.main (MavenCli.java:206)
[INFO] at jdk.internal.reflect.NativeMethodAccessorImpl.invoke0 (Native Method)
[INFO] at jdk.internal.reflect.NativeMethodAccessorImpl.invoke (NativeMethodAccessorImpl.java:62)
[INFO] at jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke (DelegatingMethodAccessorImpl.java:43)
[INFO] at java.lang.reflect.Method.invoke (Method.java:566)
[INFO] at org.codehaus.plexus.classworlds.launcher.Launcher.launchEnhanced (Launcher.java:283)
[INFO] at org.codehaus.plexus.classworlds.launcher.Launcher.launch (Launcher.java:226)
[INFO] at org.codehaus.plexus.classworlds.launcher.Launcher.mainWithExitCode (Launcher.java:407)
[INFO] at org.codehaus.plexus.classworlds.launcher.Launcher.main (Launcher.java:348)
[INFO] [ERROR]
[INFO] [ERROR]
[INFO] [ERROR] For more information about the errors and possible solutions, please read the following articles:
[INFO] [ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException
[INFO] [DEBUG] Shutting down adapter factory; available factories [file-lock, rwlock-local, semaphore-local, noop]; available name mappers [discriminating, file-gav, file-hgav, file-static, gav, static]
[INFO] [DEBUG] Shutting down 'file-lock' factory
[INFO] [DEBUG] Shutting down 'rwlock-local' factory
[INFO] [DEBUG] Shutting down 'semaphore-local' factory
[INFO] [DEBUG] Shutting down 'noop' factory
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary for Apache Wayang (incubating) 1.0.0-RC3-SNAPSHOT:
[INFO]
[INFO] Apache Wayang (incubating) ......................... FAILURE [ 23.626 s]
[INFO] Wayang Commons ..................................... SKIPPED
[INFO] wayang-utils-profile-db ............................ SKIPPED
[INFO] Wayang Core ........................................ SKIPPED
[INFO] Wayang Basic ....................................... SKIPPED
[INFO] Wayang Platform .................................... SKIPPED
[INFO] Wayang Platform Java ............................... SKIPPED
[INFO] Wayang Platform Spark .............................. SKIPPED
[INFO] Wayang Platform JDBC Template ...................... SKIPPED
[INFO] Wayang Platform Postgres ........................... SKIPPED
[INFO] Wayang Platform SQLite3 ............................ SKIPPED
[INFO] Wayang Platform Giraph ............................. SKIPPED
[INFO] Wayang Platform Apache Flink ....................... SKIPPED
[INFO] Wayang Platform Generic Jdbc ....................... SKIPPED
[INFO] Wayang API ......................................... SKIPPED
[INFO] Wayang API Scala-Java .............................. SKIPPED
[INFO] Wayang Integration Test ............................ SKIPPED
[INFO] Wayang API Python .................................. SKIPPED
[INFO] wayang-api-sql ..................................... SKIPPED
[INFO] Wayang Profiler .................................... SKIPPED
[INFO] Wayang Extensions .................................. SKIPPED
[INFO] wayang-iejoin ...................................... SKIPPED
[INFO] Wayang - Common resources .......................... SKIPPED
[INFO] wayang-benchmark ................................... SKIPPED
[INFO] Wayang ML4all ...................................... SKIPPED
[INFO] Wayang Project Assembly ............................ SKIPPED
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 24.093 s
[INFO] Finished at: 2024-06-25T10:53:32+02:00
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-release-plugin:3.0.1:perform (default-cli) on project wayang: Maven execution failed, exit code: 1 -> [Help 1]
org.apache.maven.lifecycle.LifecycleExecutionException: Failed to execute goal org.apache.maven.plugins:maven-release-plugin:3.0.1:perform (default-cli) on project wayang: Maven execution failed, exit code: 1
at org.apache.maven.lifecycle.internal.MojoExecutor.doExecute2 (MojoExecutor.java:333)
at org.apache.maven.lifecycle.internal.MojoExecutor.doExecute (MojoExecutor.java:316)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:212)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:174)
at org.apache.maven.lifecycle.internal.MojoExecutor.access$000 (MojoExecutor.java:75)
at org.apache.maven.lifecycle.internal.MojoExecutor$1.run (MojoExecutor.java:162)
at org.apache.maven.plugin.DefaultMojosExecutionStrategy.execute (DefaultMojosExecutionStrategy.java:39)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:159)
at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:105)
at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:73)
at org.apache.maven.lifecycle.internal.builder.singlethreaded.SingleThreadedBuilder.build (SingleThreadedBuilder.java:53)
at org.apache.maven.lifecycle.internal.LifecycleStarter.execute (LifecycleStarter.java:118)
at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:261)
at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:173)
at org.apache.maven.DefaultMaven.execute (DefaultMaven.java:101)
at org.apache.maven.cli.MavenCli.execute (MavenCli.java:906)
at org.apache.maven.cli.MavenCli.doMain (MavenCli.java:283)
at org.apache.maven.cli.MavenCli.main (MavenCli.java:206)
at jdk.internal.reflect.NativeMethodAccessorImpl.invoke0 (Native Method)
at jdk.internal.reflect.NativeMethodAccessorImpl.invoke (NativeMethodAccessorImpl.java:62)
at jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke (DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke (Method.java:566)
at org.codehaus.plexus.classworlds.launcher.Launcher.launchEnhanced (Launcher.java:283)
at org.codehaus.plexus.classworlds.launcher.Launcher.launch (Launcher.java:226)
at org.codehaus.plexus.classworlds.launcher.Launcher.mainWithExitCode (Launcher.java:407)
at org.codehaus.plexus.classworlds.launcher.Launcher.main (Launcher.java:348)
Caused by: org.apache.maven.plugin.MojoExecutionException: Maven execution failed, exit code: 1
at org.apache.maven.plugins.release.PerformReleaseMojo.execute (PerformReleaseMojo.java:198)
at org.apache.maven.plugin.DefaultBuildPluginManager.executeMojo (DefaultBuildPluginManager.java:126)
at org.apache.maven.lifecycle.internal.MojoExecutor.doExecute2 (MojoExecutor.java:328)
at org.apache.maven.lifecycle.internal.MojoExecutor.doExecute (MojoExecutor.java:316)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:212)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:174)
at org.apache.maven.lifecycle.internal.MojoExecutor.access$000 (MojoExecutor.java:75)
at org.apache.maven.lifecycle.internal.MojoExecutor$1.run (MojoExecutor.java:162)
at org.apache.maven.plugin.DefaultMojosExecutionStrategy.execute (DefaultMojosExecutionStrategy.java:39)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:159)
at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:105)
at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:73)
at org.apache.maven.lifecycle.internal.builder.singlethreaded.SingleThreadedBuilder.build (SingleThreadedBuilder.java:53)
at org.apache.maven.lifecycle.internal.LifecycleStarter.execute (LifecycleStarter.java:118)
at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:261)
at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:173)
at org.apache.maven.DefaultMaven.execute (DefaultMaven.java:101)
at org.apache.maven.cli.MavenCli.execute (MavenCli.java:906)
at org.apache.maven.cli.MavenCli.doMain (MavenCli.java:283)
at org.apache.maven.cli.MavenCli.main (MavenCli.java:206)
at jdk.internal.reflect.NativeMethodAccessorImpl.invoke0 (Native Method)
at jdk.internal.reflect.NativeMethodAccessorImpl.invoke (NativeMethodAccessorImpl.java:62)
at jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke (DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke (Method.java:566)
at org.codehaus.plexus.classworlds.launcher.Launcher.launchEnhanced (Launcher.java:283)
at org.codehaus.plexus.classworlds.launcher.Launcher.launch (Launcher.java:226)
at org.codehaus.plexus.classworlds.launcher.Launcher.mainWithExitCode (Launcher.java:407)
at org.codehaus.plexus.classworlds.launcher.Launcher.main (Launcher.java:348)
Caused by: org.apache.maven.shared.release.ReleaseExecutionException: Maven execution failed, exit code: 1
at org.apache.maven.shared.release.phase.AbstractRunGoalsPhase.execute (AbstractRunGoalsPhase.java:115)
at org.apache.maven.shared.release.phase.RunPerformGoalsPhase.runLogic (RunPerformGoalsPhase.java:127)
at org.apache.maven.shared.release.phase.RunPerformGoalsPhase.execute (RunPerformGoalsPhase.java:59)
at org.apache.maven.shared.release.DefaultReleaseManager.perform (DefaultReleaseManager.java:325)
at org.apache.maven.shared.release.DefaultReleaseManager.perform (DefaultReleaseManager.java:268)
at org.apache.maven.plugins.release.PerformReleaseMojo.execute (PerformReleaseMojo.java:196)
at org.apache.maven.plugin.DefaultBuildPluginManager.executeMojo (DefaultBuildPluginManager.java:126)
at org.apache.maven.lifecycle.internal.MojoExecutor.doExecute2 (MojoExecutor.java:328)
at org.apache.maven.lifecycle.internal.MojoExecutor.doExecute (MojoExecutor.java:316)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:212)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:174)
at org.apache.maven.lifecycle.internal.MojoExecutor.access$000 (MojoExecutor.java:75)
at org.apache.maven.lifecycle.internal.MojoExecutor$1.run (MojoExecutor.java:162)
at org.apache.maven.plugin.DefaultMojosExecutionStrategy.execute (DefaultMojosExecutionStrategy.java:39)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:159)
at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:105)
at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:73)
at org.apache.maven.lifecycle.internal.builder.singlethreaded.SingleThreadedBuilder.build (SingleThreadedBuilder.java:53)
at org.apache.maven.lifecycle.internal.LifecycleStarter.execute (LifecycleStarter.java:118)
at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:261)
at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:173)
at org.apache.maven.DefaultMaven.execute (DefaultMaven.java:101)
at org.apache.maven.cli.MavenCli.execute (MavenCli.java:906)
at org.apache.maven.cli.MavenCli.doMain (MavenCli.java:283)
at org.apache.maven.cli.MavenCli.main (MavenCli.java:206)
at jdk.internal.reflect.NativeMethodAccessorImpl.invoke0 (Native Method)
at jdk.internal.reflect.NativeMethodAccessorImpl.invoke (NativeMethodAccessorImpl.java:62)
at jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke (DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke (Method.java:566)
at org.codehaus.plexus.classworlds.launcher.Launcher.launchEnhanced (Launcher.java:283)
at org.codehaus.plexus.classworlds.launcher.Launcher.launch (Launcher.java:226)
at org.codehaus.plexus.classworlds.launcher.Launcher.mainWithExitCode (Launcher.java:407)
at org.codehaus.plexus.classworlds.launcher.Launcher.main (Launcher.java:348)
Caused by: org.apache.maven.shared.release.exec.MavenExecutorException: Maven execution failed, exit code: 1
at org.apache.maven.shared.release.exec.InvokerMavenExecutor.executeGoals (InvokerMavenExecutor.java:129)
at org.apache.maven.shared.release.exec.AbstractMavenExecutor.executeGoals (AbstractMavenExecutor.java:70)
at org.apache.maven.shared.release.phase.AbstractRunGoalsPhase.execute (AbstractRunGoalsPhase.java:105)
at org.apache.maven.shared.release.phase.RunPerformGoalsPhase.runLogic (RunPerformGoalsPhase.java:127)
at org.apache.maven.shared.release.phase.RunPerformGoalsPhase.execute (RunPerformGoalsPhase.java:59)
at org.apache.maven.shared.release.DefaultReleaseManager.perform (DefaultReleaseManager.java:325)
at org.apache.maven.shared.release.DefaultReleaseManager.perform (DefaultReleaseManager.java:268)
at org.apache.maven.plugins.release.PerformReleaseMojo.execute (PerformReleaseMojo.java:196)
at org.apache.maven.plugin.DefaultBuildPluginManager.executeMojo (DefaultBuildPluginManager.java:126)
at org.apache.maven.lifecycle.internal.MojoExecutor.doExecute2 (MojoExecutor.java:328)
at org.apache.maven.lifecycle.internal.MojoExecutor.doExecute (MojoExecutor.java:316)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:212)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:174)
at org.apache.maven.lifecycle.internal.MojoExecutor.access$000 (MojoExecutor.java:75)
at org.apache.maven.lifecycle.internal.MojoExecutor$1.run (MojoExecutor.java:162)
at org.apache.maven.plugin.DefaultMojosExecutionStrategy.execute (DefaultMojosExecutionStrategy.java:39)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:159)
at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:105)
at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:73)
at org.apache.maven.lifecycle.internal.builder.singlethreaded.SingleThreadedBuilder.build (SingleThreadedBuilder.java:53)
at org.apache.maven.lifecycle.internal.LifecycleStarter.execute (LifecycleStarter.java:118)
at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:261)
at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:173)
at org.apache.maven.DefaultMaven.execute (DefaultMaven.java:101)
at org.apache.maven.cli.MavenCli.execute (MavenCli.java:906)
at org.apache.maven.cli.MavenCli.doMain (MavenCli.java:283)
at org.apache.maven.cli.MavenCli.main (MavenCli.java:206)
at jdk.internal.reflect.NativeMethodAccessorImpl.invoke0 (Native Method)
at jdk.internal.reflect.NativeMethodAccessorImpl.invoke (NativeMethodAccessorImpl.java:62)
at jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke (DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke (Method.java:566)
at org.codehaus.plexus.classworlds.launcher.Launcher.launchEnhanced (Launcher.java:283)
at org.codehaus.plexus.classworlds.launcher.Launcher.launch (Launcher.java:226)
at org.codehaus.plexus.classworlds.launcher.Launcher.mainWithExitCode (Launcher.java:407)
at org.codehaus.plexus.classworlds.launcher.Launcher.main (Launcher.java:348)
[ERROR]
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException
[DEBUG] Shutting down adapter factory; available factories [file-lock, rwlock-local, semaphore-local, noop]; available name mappers [discriminating, file-gav, file-hgav, file-static, gav, static]
[DEBUG] Shutting down 'file-lock' factory
[DEBUG] Shutting down 'rwlock-local' factory
[DEBUG] Shutting down 'semaphore-local' factory
[DEBUG] Shutting down 'noop' factory