Wayang and the Federated AI

AI systems and applications are widely used nowadays, from assisting grammar spellings to detecting early signs of cancer cells. Building an AI requires a lot of data and training to achieve the desired results, and federated learning is an approach to make AI training more viable. Federated learning (or collaborative learning) is a technique that trains AI models on data distributed across multiple serves or devices. It does so without centralizing data on a single place or storage. It also prevents the possibility of data breaches and protects sensitive personal data. One of the significant challenges in working with AI is the variety of tools found in the market or the open-source community. Each tool provides results in a different form; integrating them can be pretty challenging. Let's talk about Apache Wayang and how it can help to solve this problem.
Apache Wayang in the Federated AI world
Apache Wayang (Wayang, for short), an Apache Software Foundation top-level project, integrates big data platforms and tools by removing the complexity of worrying about low-level details. Interestingly, even if it was not designed for, Wayang could also serve as a scalable platform for federated learning: the Wayang community is starting to work on integrating federated learning capabilities. In a federated learning approach, Wayang would allow different local models to be built and exchange its model results across other data centers to combine them into a single enhanced model.
A real-world example
Let's consider a real-world scenario. Hospitals and health organizations have increased their investments in machine/deep learning initiatives to learn more and predict diagnostics. However, due to legal frameworks, sharing patients' information or diagnostics is impossible, and the solution would be to apply federated learning. To solve this problem, we could use Wayang to help to train the models. See the diagram 1 below:
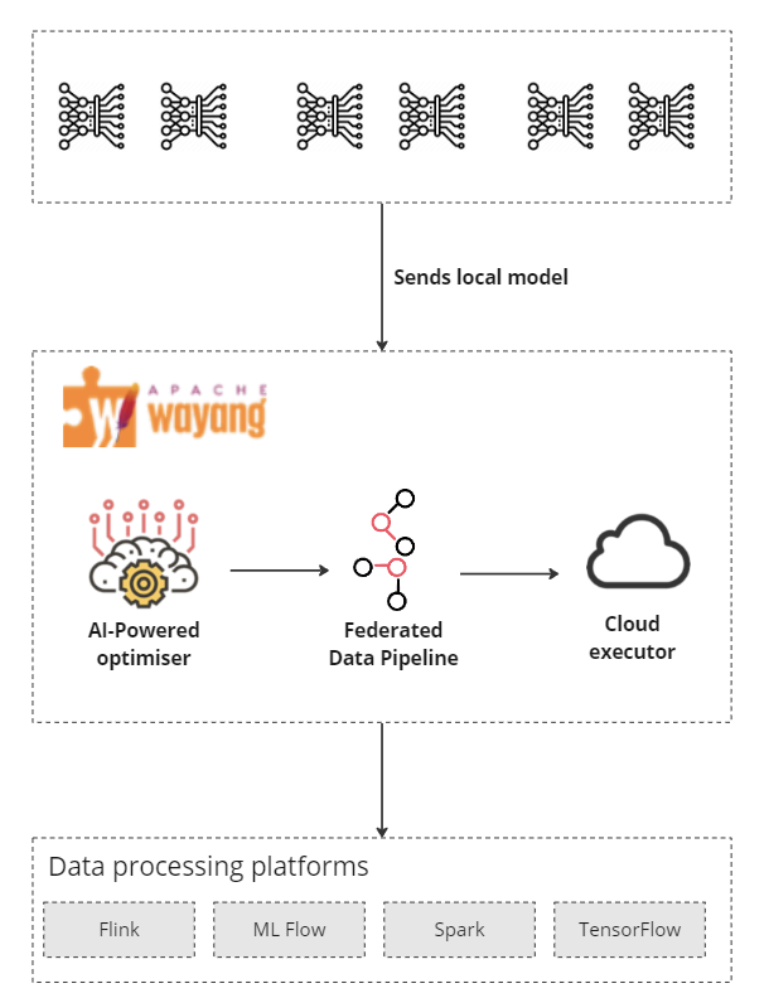
As a first step, the data scientists would send an ML task to Wayang, which will work as an abstraction layer to connect to different data processing platforms, sparing the time to build integration code for each. Then, the data platforms process and generate the results that will be sent back to Wayang. Wayang aggregates the results into one "global result" and sends it back to the requestor as a next step.
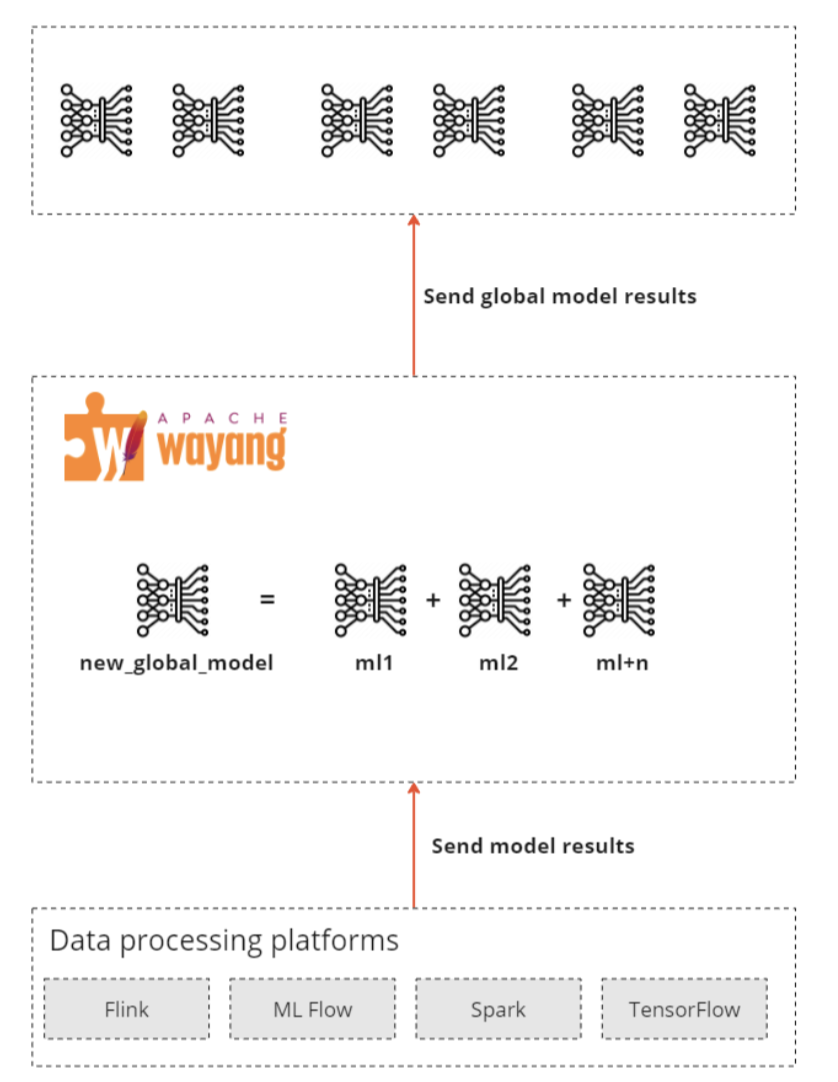
The process repeats until the desired results are achieved. Although it is very much like a Federated learning pipeline, Wayang removes a considerable layer of complexity from the developers by integrating with diverse types of data platforms. It also brings fast development and reduces the need for a deep understanding of data infrastructure or integrations. Developers can focus on the logic and how to execute tasks instead of details about data processors.
Follow Wayang
Apache Wayang is a top-level ASF project with a potential roadmap of implementations coming soon (including the federated learning aspect as well as an SQL interface and a novel data debugging functionality). If you want to hear or join the community, consult the link https://wayang.apache.org/community/ , join the mailing lists, contribute with new ideas, write documentation, or fix bugs.
Thank you!
I (Gláucia) want to thank professor Jorge Quiané for the guidance to write this blog post. Thanks for incentivate me to join the project and for the knowledge shared. I will always remember you.